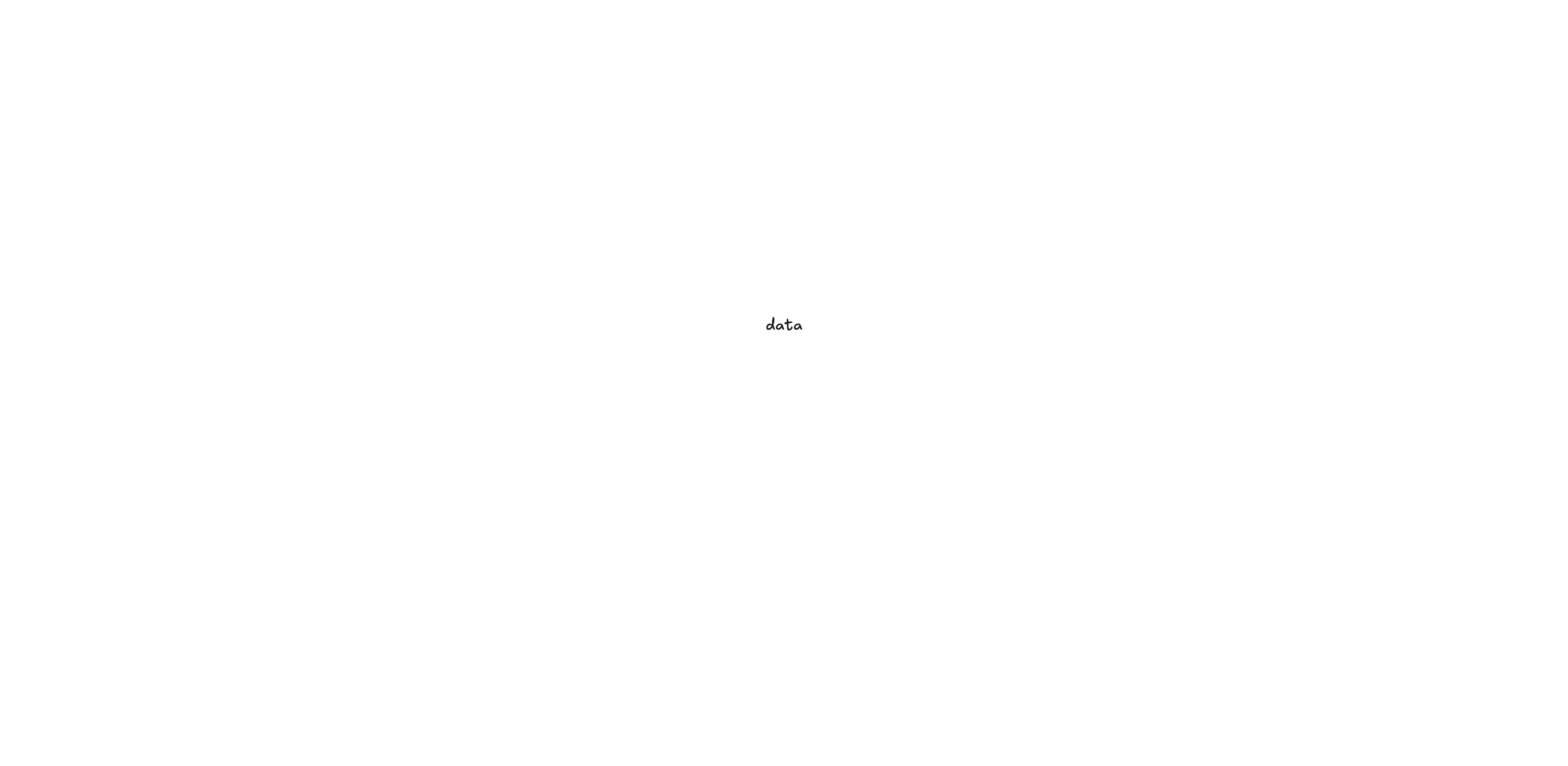
SELECT balance FROM /brand WHERE account.id = 12345678 AND account.brand = $1;
run code on the cache
Compute
Event driven
Keeping an eye on things
Hit Rate
Miss Rate
PUT Latency
GET Latency
Sync Queue Depth
Leader Election Events
Replication Failures
Where next?
A quest for speed
Caching, data grids, and more
Presented: 2025-01-29
Over the course of my career I've found myself in the middle of a number of incidents that have, at least in part, involved caching. Thankfully, most of these have gone largely unnoticed. Some, particularly in the early days of Black Friday, made the headlines.
Caches are everywhere, many of them invisible. Without them we wouldn't have access to the information and services we do today.
Caches can be large and physical. This photo shows a decommissioned 2013 Netflix cache server. These were deployed in key ISP locations and used to cache video data for popular Netflix content. By holding this video data closer to users, Netflix was able to achieve predictable performance and significantly reduce data transfer costs.
This particular unit was acquired by a Reddit user (after it had been decommissioned). This particular cache was light on CPU, only a single Intel Xeon processor (10 cores / 20 threads. However it was heavy on storage, 36 8TB spinning disks and six 500GB SSDs. This gave Netflix 262TB or local storage per cache deployed.
But caches can also be small. Here we have a die shot of an Intel i9. The repetitive pattern running horizontally across the die shot shows the various levels on on die cache used to accelerate CPU performance.
In this talk we are going to explore the humble cache in the context of two specific examples.
🍪
Session Cookies
Tracks state through the life of a user session
💳
Account Balance
Increasing demand for up-to-date information
We will look at the need for caching, referencing industry examples and trends where necessary but will use these two examples to illustrate some of the design considerations made when deploying a cache.
We'll finish with a look at some of the more creative architectural solutions that have evolved from caching technology.
⏳ We don't like waiting
If we wanted to simplify the reason we deploy caching in systems, it is this. We don't like waiting.
But why? Why do things need to be fast?
We build applications to help people complete specific tasks. Often these tasks appear to be simple transactional operations but behind the simplest of customer interactions is often an interconnected web of business processes that need to be followed to ensure customers get the results they expect, compliance processes are followed, financial records are updated, etc. Coordinating this complexity is what makes the applications we build so incredibly useful.
The fact that customers are unaware of much of this complexity is a testament to the work of the teams that build our applications. When things work well, users can complete complex tasks at the click of a button.
When things don't work well, people get frustrated. They may try again later, use a different approach, or they may complain and give up.
But are we really so sensitive to delays in response times? This is an interesting question and it turns out one that people have tried to measure.
Time is money
Site speed directly impacts the rate at which users complete a desired outcome.
We are so sensitive to changes in page response times that significant research has been done to understand this sensitivity.
The FT conducted tests that showed readers read noticeably less as page load times decreased. They found that this effect was sustained over time. The longer the slow down, the less people were reading.
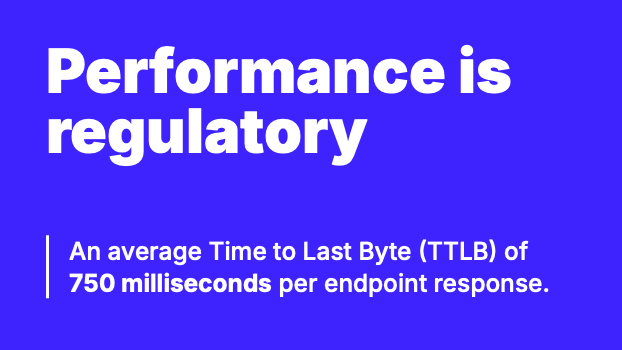
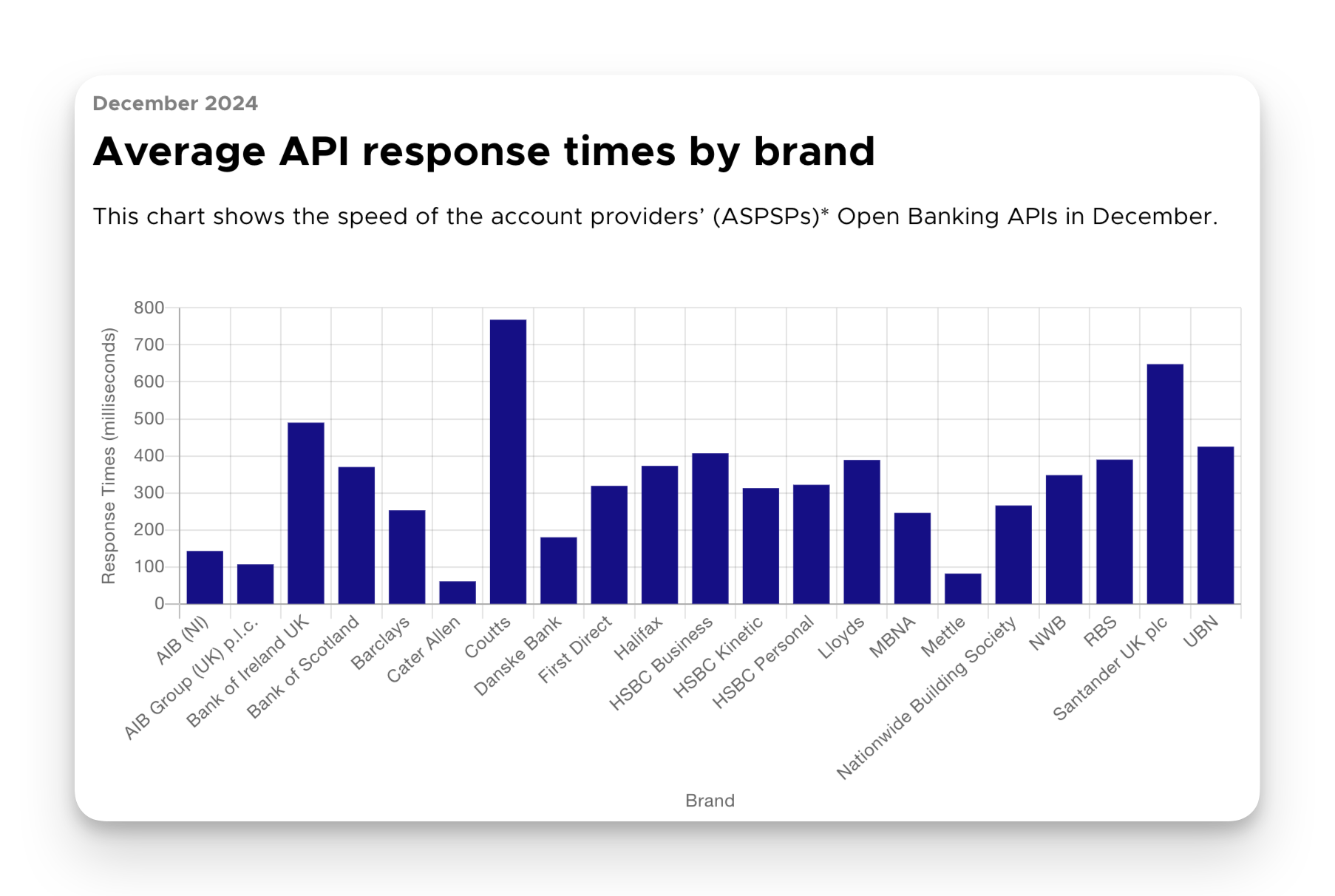
An average Time to Last Byte (TTLB) of 750 milliseconds per endpoint response.
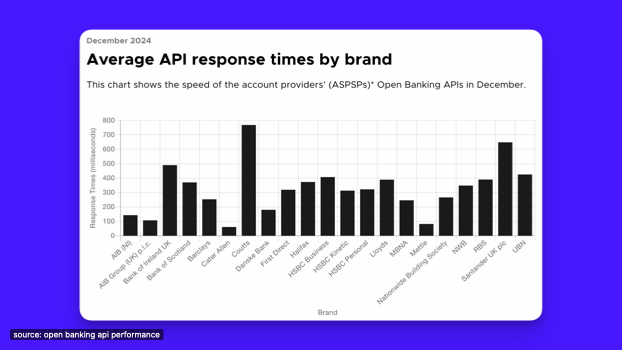
The Open Banking regulations include expected performance characteristics for service response times. Transactions across the following areas are all required to achieve a Time to Last Byte (TTLB) of 750ms.
So we've established that performance is important. We've seen research that quantifies how important that is in terms that we can use to justify spending time on making things quicker.
But why is performance hard? What is it about the design of our systems that makes achieving desired response times so difficult?
Part of that is bloat. We've already seen the trend in pages sizes. The reasons for this bloat are almost certainly the subject for a different talk. But, as an industry we've put so much effort into accelerating the developer experience whilst relying on hardware advances to keep things running fast. There is good justification for this. The cost of hardware has come down whilst developer costs have increased. It has been more important to make development faster than it has been to chase page load times.
But this isn't the only reason that performance is hard. To understand more we need to look at how services have evolved.
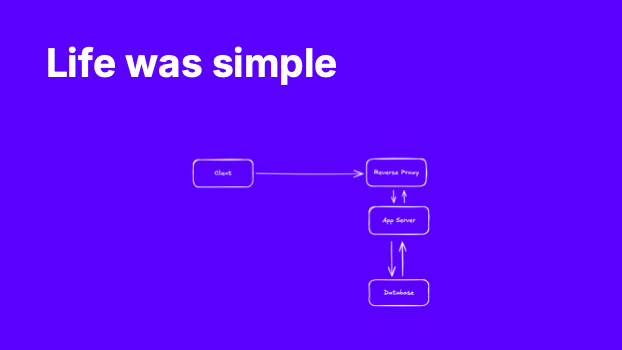
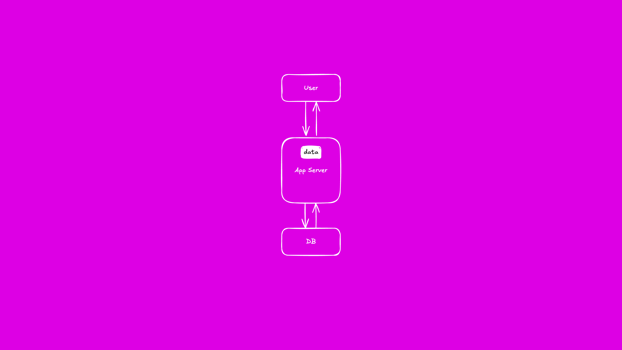
Life was simple
Many early services followed a simple pattern. Users requested pages from an application server which pulled data from a database. The application server would render the page and return it to the user.
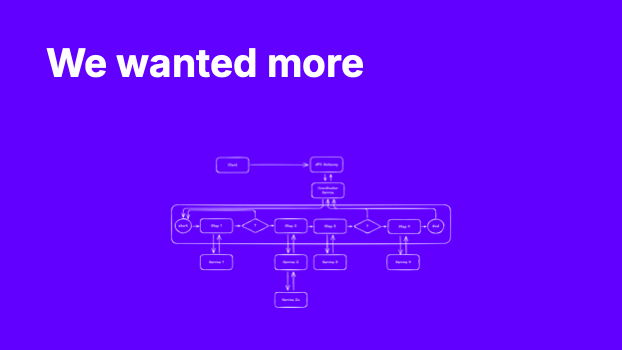
We wanted more
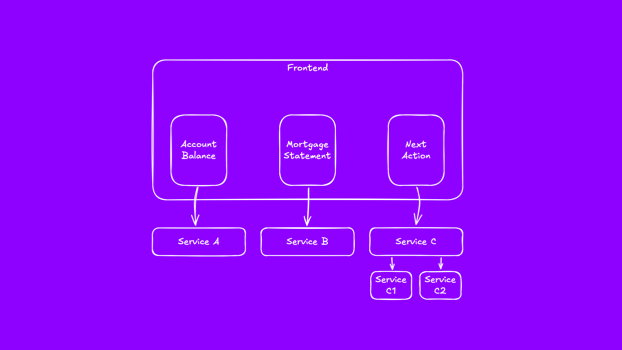
This is an example from an application that I looked at recently. I've re-drawn the diagram and simplified for this talk. What is important is the comparison with the previous image. We started asking our services to do more.
As we codified increasingly complex business processes in software, our service designs evolved. Here requests arrive at a single coordinator service which, as its name suggests, coordinates a series of subsequent requests to different systems. In the event of failure, it needs to coordinate any necessary roll-back.
Ignoring the functionality being implemented by this particular service, the implications on performance should start to be evident. Imagine that underneath each of these backing services is at least one database call, or perhaps a round trip across an asynchronous series of queues. With each of these happening sequentially, the user is left waiting longer for a response.
This is a diagram from a talk on the Monzo microservices architecture. Each blue line represents a potential service call. Trying to reason about system performance with architectures like this is a real challenge. Microservices changed the way we architected systems.
Microservices!
Microservices are both a blessing and a curse. The promise of independently deployable services allowing smaller teams to iterate with ever increasing pace was enticing enough that everyone jumped on board. But microservices are, and always were one architectural style among many. And as with everything in the domain of architecture, they were a tradeoff.
Even with the supporting teams and tools at your disposal, reaching for microservices introduces complexities. One of those is around performance.
Sequential service calls all incur a performance overhead. Users didn't give us a free pass to slow things down just because we adopted microservices. We now found ourselves having to coordinate multiple service calls each with their own calls to data stores but having to do so in the same overall page load budget we'd had before.
On top of that, the performance characteristics of one service now had the ability to have a knock on impact on the performance characteristics of the system as a whole, often in ways that are hard to reason about.
A quick aside
Front-end design
But it isn't all bad. It turns out we can use the move to microservices to our advantage and trick users into thinking that things are moving faster than ever. Front end design has evolved to give users the performance of native applications delivered on top of complex microservice architectures.
There have been a number of shifts in the way front-ends have been architected; client-side rendering, micro front-ends, and single page applications. With each of these we see a shift away from treating the page in the browser as a single request. Different page components are now rendered in response to individual service calls. It is now common to see some parts of a page taking longer to render than others. It is possible to give users the basics up front and then progressively enhance the experience as more complex operations complete. A good example of this is the "related products" or "you might also like" features on all sites today.
But I mention this is an aside only to acknowledge that this talk on caching is a vast simplification. Caches are deployed alongside any number of other architectural patterns in search of overall performance.
There isn't one magic solution that makes things faster. We are making continual tradeoffs with all parts of the system working together to deliver an experience that users enjoy.
But, back to caching.
Caching
provides stateless processes with fast access to temporary data
What does a cache do? In essence, a cache provides stateless processes with fast access to temporary data. There is nothing in here about how fast, or where that data should be stored. Indeed there is nothing that says what form the data should take or how it should be accessed.
In the earlier examples of caches from both Netflix and Intel we saw two very different implementations serving different needs.
Now that we know what a cached does, it is useful to understand what types of data we can store in it.
"when given the same arguments, if a service call yields the same results every time, then it is a good candidate for caching"
We've talked about things being fast, and how caches might be able to help by providing fast access to temporary data. But we've said very little around how fast a cache should be. How do we know when something is too slow and we should reach for a cache? There is no definitive rule that tells us how fast something should be, but there are two things to bear in mind when evaluating the use of a cache.
The first question to consider is whether your system can keep up with the rate of requests received? If not, evaluating a cache may help.
But to evaluate whether a cache will provide any significant benefit, awareness of some indicative performance numbers is helpful.
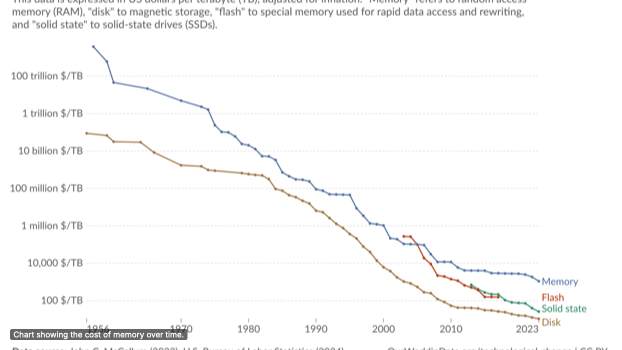
Looking at that table, one thing stands out. It may not be a surprise to see that memory is faster than disk, but knowing how much faster things can be if stored in memory leaves us with one conclusion; put everything in memory.
There are a couple of challenges to this;
cost - memory is relatively expensive
persistence - data in memory is not persisted
The cost of memory has come down significantly and dedicated caching solutions have been developed to handle the challenge of persistence.
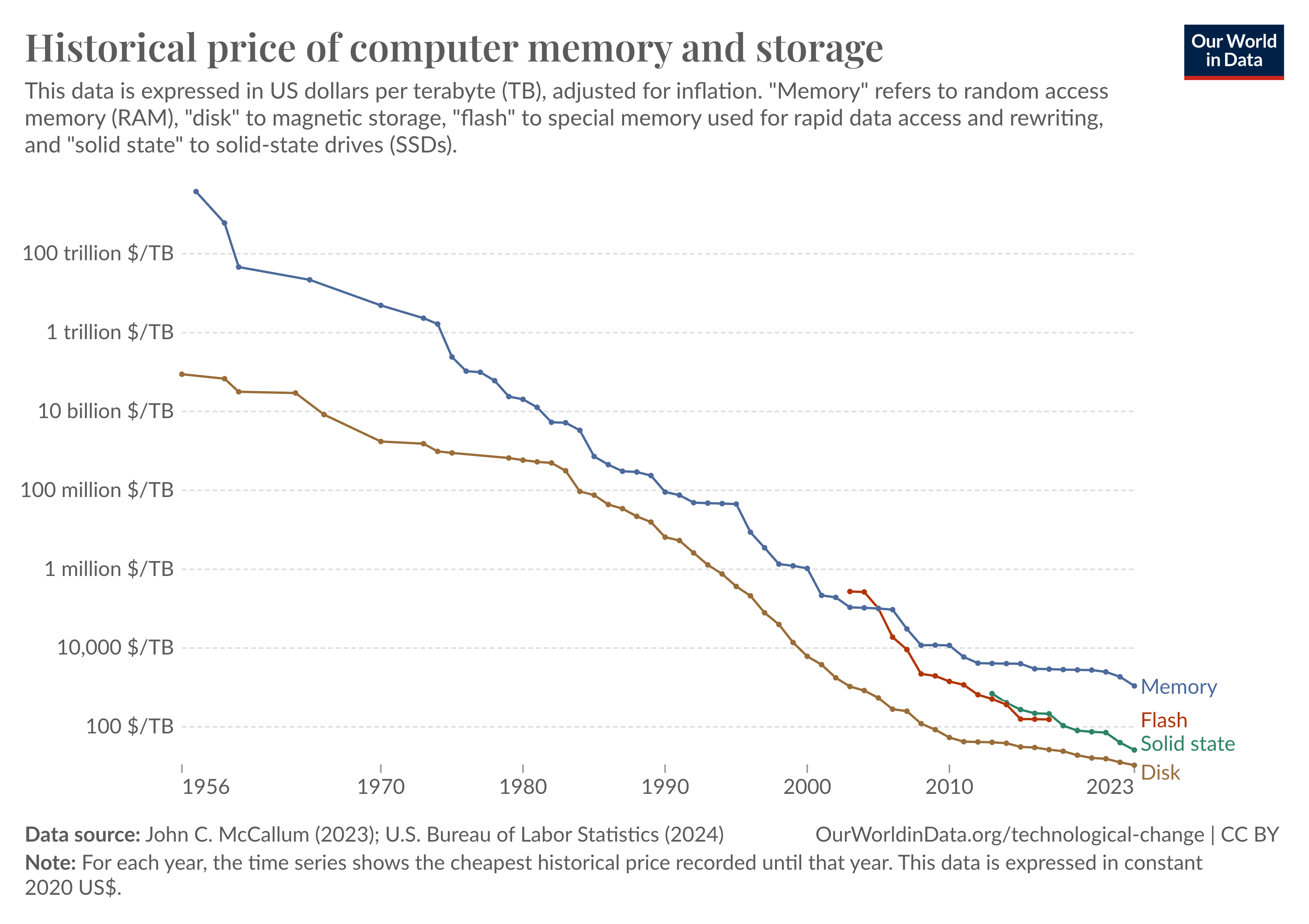
Chart showing the cost of memory over time.
This graph shows how the cost of memory has come down significantly over time. This has made it possible to deploy an in memory cache for services.
Now that we've established that we can use an in memory cache, I'd like to walk through the example of storing session identifiers using a cache.
Session data is used to track state over the life of a user session. As a user navigates a web application, they make a series of independent requests to back end services. These requests know nothing about each other unless we provide a mechanism for tracking state. One way this is commonly done is to set what is called a session cookie. This cookie contains an identifier that is passed along with each request to back-end services. This identifier can then be used to look up information about the user session; their real name, authorisation status, previous requests, etc.
Application developers need somewhere to store the mapping between this identifier and session information. This could be in the database but it is temporary and needs to be retrieved on every request to the service. It is a great candidate for caching.
To keep things simple, let's consider the mapping between a session identifier and two pieces of information; the user's real name, and their authentication status.
Rather than persist this data to an external data store, an application developer may choose to keep this in memory. They could use something like a hash map to tie session state (real name and authentication status) to an identifier. When a request comes in, they look up the identifier in the map. If it is found, they are able to display the real name and the contents of the page. If not, then this user does not have an active session. We can't show them their real name. But more importantly we have no way of identifying who they are and so we have no option but to show them a log in page.
This approach works, but it presents some challenges.
But 12 Factor says...
For anyone familiar with the 12 Factor app guidelines (or the subsequent derivatives) you are probably itching to tell me what is wrong with this.
Our applications should be stateless. See 12factor #6.
For our application to be stateless we can't store state in memory. But applications will always store some state in memory. The question we need to answer is; how much state can we store in process memory?
This is ultimately a call that the application developer will need to make based on their understanding of the use-case. However, 12 Factor does provide us some sensible guidance
The memory space or filesystem of the process can be used as a brief, single-transaction cache...
To understand why this advice is given, consider what might happen when the process terminates, crashes or restarts. All state is lost. We want to minimise the impact of the loss of a single process.
There is a second reason why we limit the scope of state to be the state required to handle a single transaction and that is scalability.
Consider what happens as we scale up the number of instances of our application.
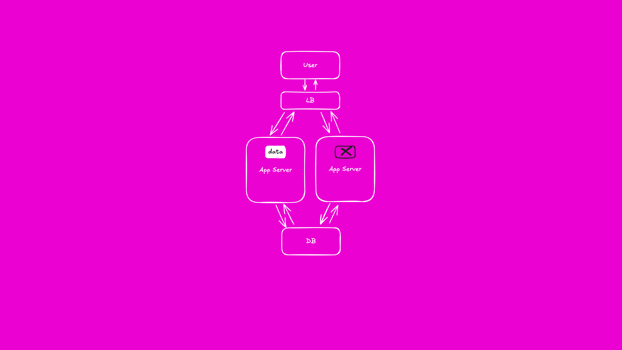
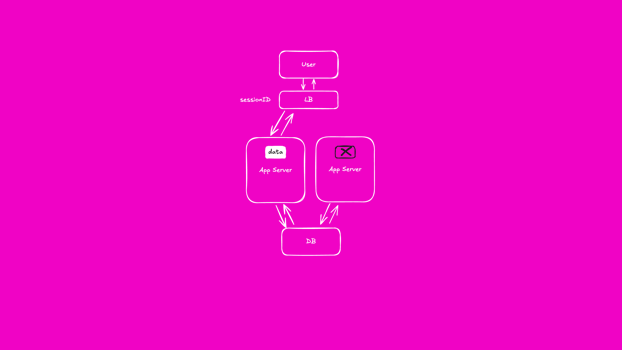
In our example, a user who logs in will have a valid session persisted in the memory of our application. We are able to see that they are logged in and display their real name at the top of the page. They then click on a menu and a new request is made to our application, passing with it the identifier in the session cookie.
This request is routed to a second copy of our application. Unfortunately this instance does not share process memory with the instance that served the previous request. It knows nothing about the user session and cannot map it to either a real name or, more importantly, their authentication status. It only has one option and that is to ask the user to log in again.
With this approach to caching, we have fast access to session data. But each time a request is routed to a new instance of our application that session data is lost and our user is asked to log in again.
So, we got clever. We added functionality to our load balancers that identified the session identifier for each request and ensured that requests were routed to the same application instance every time. This avoided users being asked to re-authenticate each time their requests were served by a new application instance.
However, although this was an improvement, it still doesn't solve the challenges of service restarts. Historically we spent a lot of time trying to keep services up as long as possible. But this presents a different set of challenges. Deployments, moving services between hosts, scaling operations all became significant events that needed to be performed at times of minimal business impact. They needed to be minimised.
The desire to normalise these operations and push more frequent updates to our services gave rise to application platforms. To function effectively, these platforms require service restarts to be normal operational events with no impact on the business. They are no longer seen as significant events to be minimised.
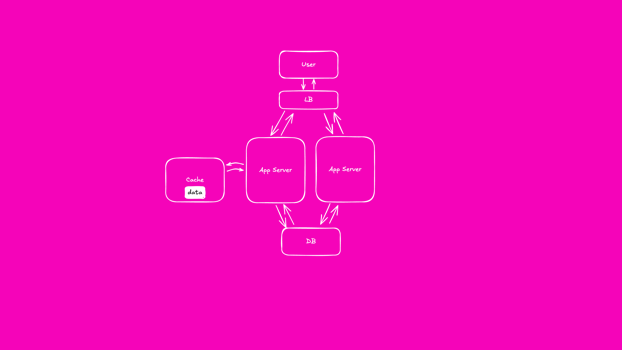
Our caching solution needs to evolve to allow our application to survive service restarts.
This gave rise to the external cache. By moving our session data outside the process memory, all application instances are now able to query session data. The data persists across process restart.
Just put it in memory
We've simplified things significantly but I'm hoping that you are now aware that caching isn't as easy as "just" putting temporary data in memory as opposed to on disk. We have to consider where in memory the data is stored and how access can be engineered to survive common service operations.
Patterns
We've talked about putting short lived data in memory temporarily to give us quick access on every request. I now want to explore how an application developer might implement this.
As with everything in software development there are standard patterns that can be followed. We aren't going to look at all of them, but we will look at two of the most common patterns to give ourselves a feel for some of the challenges involved.
This article from Hazelcast was useful in pulling together diagrams showing the common caching patterns.
Long lived data
💳 Balance
To illustrate some of the challenges with using a cache we are going to consider our second use-case; account balance.
The challenge of showing a user their account balance differs from our session cookie example in a number of ways:
persists beyond the life of a session
is updated by multiple different processes
material consequences if incorrect
The process of modifying a users account balance is significantly more involved than we'll show here. We can't, or shouldn't, be able to visit our online banking portal and set our account balance to an arbitrary figure. But, for the purposes of illustration, I want you to consider our service results in an update to the account balance.
Cache-Aside: Read
The first pattern we are going to look at is called "Cache-Aside: Read".
The cache-aside pattern has two variants; read and write. We'll start by looking at read.
1) A user requests their balance from the application
2) Application checks to see if the user's balance is stored in the cache
3) If the user's balance is present in the cache, it is used.
4) If the users's balance isn't present in the cache, it is requested from the database and then written to the cache.
5) The application returns the balance to the user.
If a value is present in the cache, the application will respond quickly. If the value isn't present then it will be populated as it is read from the database. This means the cache will now contain the value the next time it is requested.
If you can spot challenges with this pattern, hold those thoughts for now. We'll come to that.
Cache-Aside: Write
The second pattern we'll consider is the write variant of the previous example. It is simpler to implement but, as its name suggests, it only populates the cache when values are changed. A different pattern will be needed to populate the cache with data that is read but not changed frequently.
1) A user performs an action that triggers an update to their account balance.
2) The application writes the new value into the cache.
3) It then persists the value to the underlying database.
Subsequent requests for the user's account balance will now be served from the cache.
Update on read and write
Problems?
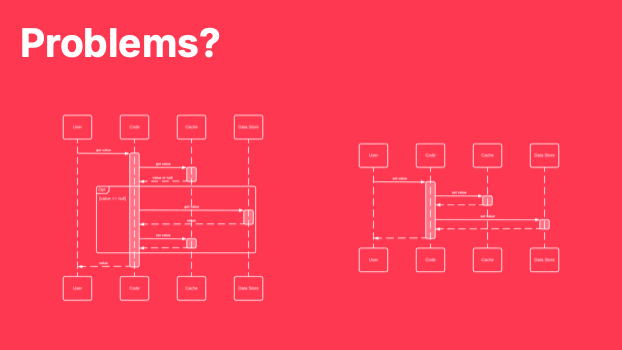
The cache-aside pattern is one of the most popular caching implementations we see. A combination of the read and write variants can ensure that the cache is populated with accurate and recent data. But, at this point, you've probably spotted at least one problem in the caching patterns described. I'll bring back both patterns so that we can explore some of the potential pitfalls.
Problems?
So let's say we implement both of these patterns. We populate our cache on read, and we update it on write.
Can anyone see any problems that we may encounter? There are definitely two, but you may find more.
Q: What happens to the size of the cache over time?
A: It grows indefinitely to match the size of our data set. If we can fit our entire dataset in memory this may not be a problem, but even with reducing memory prices this is a luxury.
Q: Is the data in the cache always guaranteed to be accurate?
A: It depends. If we can guarantee that our service is the only source of change then maybe. But what happens if the account balance is updated outside of a user request? A batch run for example?
Another potential issue isn't so much a challenge with the implementation, but a use-case that doesn't fit with this pattern. If we extend our account balance example and say that now our users want to be notified of a change in their account balance. Let's say a payment is taken from their account by a different service. Given this architecture, how would we send this notification?
It would be challenging; first our application would need to poll regularly for the account balance of all users and compare this to previous values. From a caching perspective, these polling requests would need to go to the source database every time in order to ensure the most up-to-date balance was received.
This leads me on to a different approach to caching; the refresh ahead pattern.
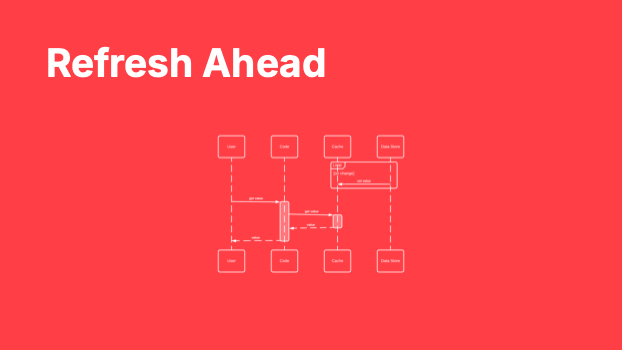
Refresh Ahead
The refresh ahead caching approach doesn't quite get us our account balance notifications but it gets us significantly closer.
1) A process continuously monitors for changes in data in the database and populates the cache.
2) A user requests their account balance.
3) The application retrieves the account balance from the cached, confident it contains the latest value.
With this pattern, the cache becomes the source of truth for our application. Our primary data store is now responsible for updating the cache contents on change. Our application is free to read data as often as it likes without incurring the penalty of going to the source of the data.
Challenges
Caching sounds too good to be true. In many systems caches are essential to system stability, availability, and performance. But, as with all tools in the system architects toolbox, the use of a cache is a trade off. That trade off presents us with a number of challenges.
We'll take a high level look at three of these.
Invalidation
Thundering Herd
Mental Model
Invalidation
If data changes at source, what value should be returned from the cache?
In our walk through of the cache-aside read and write patterns, you may have noticed that we never removed any values from our cache.
This presents us with two problems. The first is that the cache will keep filling up indefinitely. We will eventually reach the physical limit of the hardware and need to remove entries from memory to make space for new items. This raises a question that we haven't yet discussed. When should we remove items from our cache? And, when we do, which items should be removed? This is known as cache invalidation and it is regarded as a hard problem. There is no right answer and the approach you take will have direct implications for the performance of the system.
Another reason for invalidating entries in our cache is that they may no longer be valid. In the account balance example it might be that another process has updated the account balance. The value we hold in the cache is now invalid or stale and we have no way of knowing that this is the case.
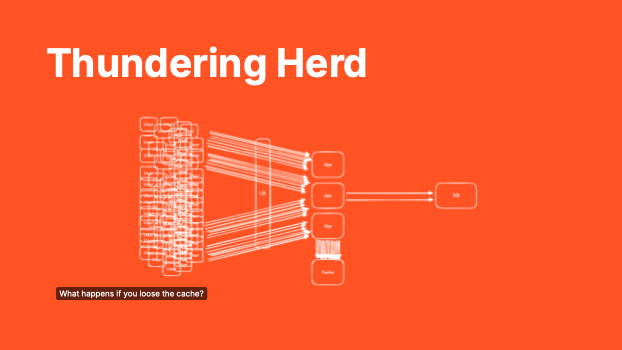
Thundering Herd
What happens if you loose the cache?
With caching in place, we are able to serve many more requests than would otherwise be possible. By responding quickly, we are not only keeping our users happy, we are freeing up vital resources to service new requests. With our cache working well, we reduce the load on slower, more critical components of our system.
If our cache ever runs into trouble, the thundering heard of requests will be directed directly at our database which we know is unable to sustain the volume. Even if we manage to restart our cache, it will be empty. The database, suffering under the volume of requests, will remain unable to respond to allow our applications to populate the cache. We can find ourselves struggling to bring the system back online.
With caches in play, our operations teams need to understand system behaviour in the even of issue and have the experience needed to bring the system back online.
Resilience
We are familiar with how to deploy applications that are resilient across multiple sites. We have not considered how we might make our caching solution available on multiple sites. I'll leave this as a challenge for you to consider afterwards. The challenge is guaranteeing you write data to multiple sites consistently (and fast).
Multi-Layer Caching
Between a user and the primary data store there are often multiple different caches.
As we've talked through caching patterns, we've looked at a system that contains only one cache. In reality there are multiple layers of caching available in most complex systems and this makes reasoning about how the system will behave much harder.
And this brings me on to the final challenge that I want to talk about today.
Mental Model
When we build and run complex systems involving the interaction between many different components. It can be hard to retain a mental model of how the system behaves. As we introduce caching, particularly the interaction of multiple layers of caching, system performance can surprise us. Surprise is not typically what operations teams look for.
If you'd like good examples of how painful it can be to reason about system behaviour where caches are involved talk to your friendly operations teams.
One great example is this collection of incidents involving 'the cache' at Twitter. It highlights how difficult it can be to reason about system behaviour.
"a collection of information on severe (SEV-0 or SEV-1 incidents at Twitter that were at least partially attributed to cache"
What if we stopped treating our caches as temporary data stores born out of the need for speed? What if we started considering them data stores in their own right? What if we introduced computation?
Introducing the data grid...
SQL queries
SELECT balance FROM /brand WHERE account.id = 12345678 AND account.brand = $1;
We've talked about our cache as a place where we can put and get values. We haven't said much about what these values might be. By far the most common is the idea of a 'key: value' store. You use an identifier to persist and retrieve a value.
But caching solutions have evolved to allow more complex queries to be asked of the cached data. This even extends to writing SQL like queries against the cache. The cache starts to look like a distributed in-memory database, or a data grid.
run code on the cache
Compute
One premise of caching is that it brings data closer to where it is needed. This doesn't have to mean physically closer, rather faster access times. But, what can we do if we bring the compute to the data? By allowing users to run computational tasks within the cache we have what has become known as an in-memory data grid.
Typically the tasks that are run are simple but are executed across large data sets. Fraud detection or pattern recognition is a common use case.
Event driven
I want to come back to this diagram showing the refresh-ahead pattern that we saw earlier. Now consider how it might change if we were able to run functions on the cache.
In our account balance example, a published change to account balance would populate the cache. The cache could then take action, triggering a notification service that subsequently sends a push notification to the user. If the user takes action based on that notification, our cache already contains the up-to-date account balance.
Keeping an eye on things
We've seen how we can deploy a cache to improve performance by storing data in memory closer to where it is needed. Doing so allows us to meet user expectations with the associated revenue implications. It also allows us to meet regulatory targets. In many cases we wouldn't be able to meet these demands without resorting to caching.
Cache failures can trigger system failures. Falling back to poorly protected source systems can trigger a cascading series of failures. Treating our caches as critical components of our systems requires us to keep an eye on them.
Caching technologies are different but, just as with services and systems, there are some golden signals that we can monitor to give us an indication of cache performance.
Hit Rate
Miss Rate
PUT Latency
GET Latency
With these metrics, there are no defined thresholds that indicate the cache is healthy or not. They need to be considered in the context of application or service performance. Learning how the system behaves is crucial to successful operations.
If you are using a cache cluster or cross-site replication then there will be other metrics to consider.
Sync Queue Depth
Leader Election Events
Replication Failures
Knowing that system behaviour has changed is one thing. Understanding the implications can be difficult. It is rare to see cache failure scenarios covered in testing and so, for many teams, discovering how to restart services while under load, or how to recover from replication failure are often left to the incident management process.